Pada Part 1, kita sudah membahas mengapa transaksi terdistribusi di microservices tidak bisa lagi mengandalkan satu transaksi ACID lintas semua service, lalu memperkenalkan Saga Pattern sebagai pendekatan untuk mencapai eventual consistency melalui rangkaian local transaction dan compensating transaction. Pada Part 2 ini, kita masuk ke implementasi pertama: Choreography-Based Saga, yaitu pendekatan di mana setiap service berkomunikasi melalui event tanpa adanya pengendali pusat atau orchestrator tunggal. Choreography adalah salah satu model utama saga, terutama untuk workflow yang relatif sederhana dan berbasis event.
Sebagai ilustrasi, choreography saga mirip seperti tarian tanpa sutradara tunggal atau permainan banyak alat musik tanpa orkestrator, satu service menerbitkan event, service lain yang mendengar event tersebut lalu melakukan pekerjaannya, kemudian menerbitkan event berikutnya. Pendekatan ini tidak ada central coordinator, jadi masing-masing service bertanggung jawab mengetahui event apa yang perlu didengar dan tindakan apa yang harus dijalankan ketika event itu diterima. Konsekuensinya, coupling antar-service bisa lebih longgar, tetapi business flow menjadi menyebar ke banyak tempat dan lebih sulit ditelusuri ketika sistem tumbuh menjadi lebih kompleks.
Kenapa mulai dari choreography?
Dalam banyak sistem microservices, event-driven communication adalah pola yang paling natural, service menyelesaikan local transaction, lalu menerbitkan event agar service lain dapat melanjutkan proses. Choreography cocok untuk workflow sederhana yang hanya melibatkan sedikit service dan tidak membutuhkan coordination logic yang terlalu rumit. Choreography juga merupakan opsi yang menarik ketika kita ingin memanfaatkan fitur publish/subscribe dan menjaga service tetap saling independen. Jadi jika anda sudah memiliki arsitektur microservices berbasis message broker, consumer, dan event handlers di .NET, choreography dapat menjadi pilihan langkah selanjutnya. Namun penting dicatat sejak awal bahwa pendekatan ini bukan tanpa trade-off. Pada choreography, workflow dapat menjadi membingungkan ketika jumlah langkah bertambah, integrasi testing menjadi lebih sulit, dan ada risiko cyclic dependency jika antar services pada saga saling bergantung secara tidak tepat, Jadi walaupun saga menghindari distributed transaction tradisional, developer tetap harus merancang kompensasi dan konsistensi alur secara lebih eksplisit.
Apa itu Choreography-Based Saga?
Dalam choreography-based saga, setiap local transaction melakukan dua hal
- Memperbarui state atau data di databasenya sendiri, dan
- Membuat event yang akan memicu langkah berikutnya di service lain.
Tidak ada orchestrator pusat yang menyimpan seluruh urutan langkah. Sebaliknya, urutan bisnis “terbentuk” dari rangkaian event yang saling memicu. Pada model choreography, service bertukar event tanpa centralized controller. Contoh pada aplikasi e-commerce: Order Service menerbitkan OrderCreated, lalu Payment Service mendengarnya, memproses pembayaran, dan menerbitkan event lanjutan yang didengar oleh service berikutnya.
Secara arsitektural, model ini sangat cocok dengan metode publish/subscribe. Satu event bisa dikonsumsi oleh satu atau beberapa service, dan setiap service hanya perlu tahu “kalau event X datang, saya harus melakukan Y.” Keuntungan pendekatan ini adalah service tidak perlu memiliki pengetahuan penuh tentang seluruh workflow bisnis. Kelemahannya, untuk memahami alur end-to-end, Anda harus menelusuri event dari satu service ke service lain, bukan membaca satu orchestrator tunggal.
Contoh Skenario: Checkout order
Agar memberi gambaran konkret, kita akan menggunakan skenario checkout dengan empat service:
Order Servicemembuat order dan menyimpan status awal.Payment Servicememproses pembayaran atau payment authorization.Inventory Servicemereservasi stok.Shipping Servicemenjadwalkan pengiriman.
Pada pendekatan choreography, alurnya kira-kira seperti ini:
Order Servicemenerima request order, menyimpan order dengan statusPending, lalu menerbitkan eventOrderCreated.Payment ServicemendengarOrderCreated, memproses pembayaran, lalu menerbitkanPaymentSucceededatauPaymentFailed.Inventory ServicemendengarPaymentSucceeded, mencoba reserve stok, lalu menerbitkanInventoryReservedatauInventoryFailed.Shipping ServicemendengarInventoryReserved, menjadwalkan pengiriman, lalu menerbitkanShipmentScheduled.Order Servicemendengar event akhir sepertiShipmentScheduled, lalu mengubah status order menjadiCompleted.
Jika salah satu langkah gagal, misalnya inventory gagal setelah payment sukses, maka event kompensasi diterbitkan untuk membalikkan efek bisnis dari langkah-langkah yang sudah berhasil, misalnya PaymentRefunded lalu OrderCancelled.
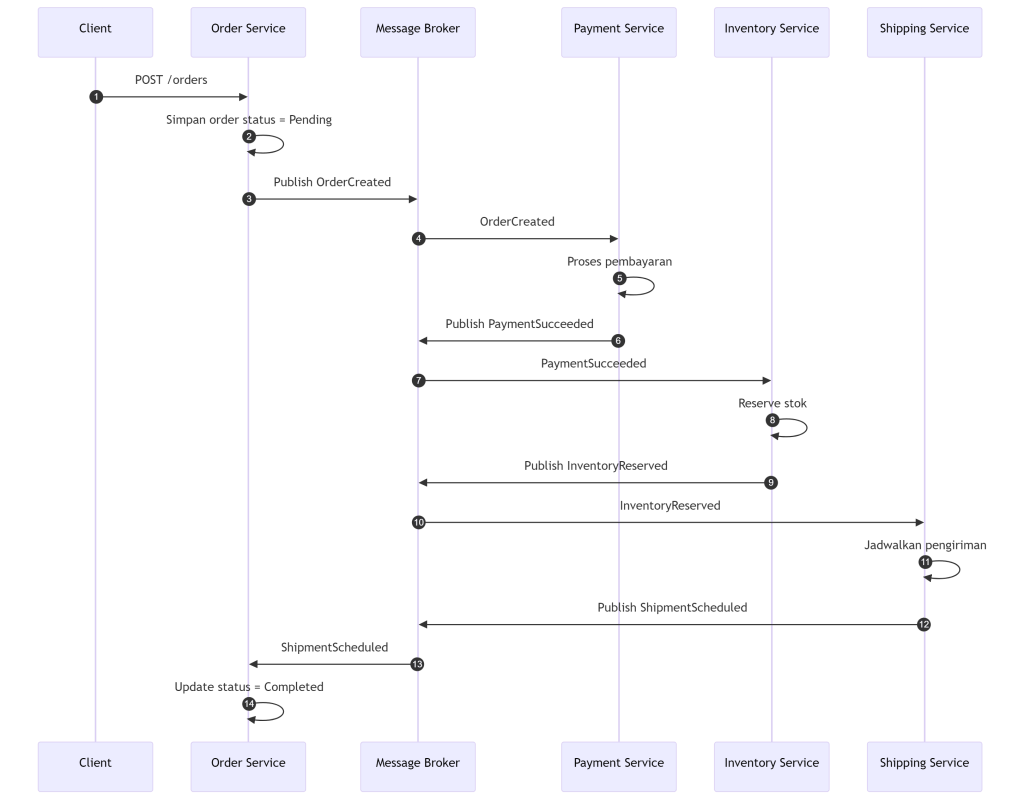
Diagram diatas mencerminkan prinsip choreography yaitu setiap service bereaksi terhadap event, menjalankan local transaction, lalu menerbitkan event berikutnya. Tidak ada satu komponen pusat yang “menyuruh” step berikutnya, yang ada adalah rangkaian reaksi terhadap event.
Contoh event contract di .NET
Pada implementasi .NET, langkah pertama biasanya adalah mendefinisikan event contract yang akan dipertukarkan antar-service. Event ini sebaiknya kecil, fokus pada fakta bisnis, dan membawa data minimum yang dibutuhkan service berikutnya untuk menjalankan langkahnya. Ini sejalan dengan praktik event-driven.
public record OrderCreated( Guid OrderId, Guid CustomerId, decimal TotalAmount);public record PaymentSucceeded( Guid OrderId, string PaymentReference);public record PaymentFailed( Guid OrderId, string Reason);public record InventoryReserved( Guid OrderId);public record InventoryFailed( Guid OrderId, string Reason);public record ShipmentScheduled( Guid OrderId, string ShipmentNumber);public record PaymentRefunded( Guid OrderId);public record OrderCancelled( Guid OrderId, string Reason);``
Walaupun bentuk event bisa berbeda-beda sesuai kebutuhan domain, prinsip dasarnya sama yaitu event merepresentasikan sesuatu yang sudah terjadi, bukan instruksi imperatif seperti command. Pada choreography, peran event memang sangat sentral karena event adalah mekanisme utama yang menghubungkan local transaction antar-service.
Langkah 1: Order Service
Service pertama dalam alur adalah Order Service. Ia menerima HTTP request dari client, menyimpan order, lalu menerbitkan event OrderCreated untuk memulai saga. Pada pola ini satu event awal menjadi pemicu seluruh rantai transaksi berikutnya.
public class Order{ public Guid Id { get; set; } public Guid CustomerId { get; set; } public decimal TotalAmount { get; set; } public string Status { get; set; } = "Pending";}public interface IOrderRepository{ Task SaveAsync(Order order); Task<Order?> GetByIdAsync(Guid orderId); Task UpdateStatusAsync(Guid orderId, string status);}public interface IMessageBus{ Task PublishAsync<T>(T message);}app.MapPost("/orders", async ( CreateOrderRequest request, IOrderRepository repository, IMessageBus bus) =>{ var order = new Order { Id = Guid.NewGuid(), CustomerId = request.CustomerId, TotalAmount = request.TotalAmount, Status = "Pending" }; await repository.SaveAsync(order); await bus.PublishAsync(new OrderCreated( order.Id, order.CustomerId, order.TotalAmount)); return Results.Accepted($"/orders/{order.Id}", new { order.Id });});public record CreateOrderRequest(Guid CustomerId, decimal TotalAmount);``
Langkah 2: Payment Service merespons OrderCreated
Setelah OrderCreated diterbitkan, Payment Service akan mendengarnya dan mencoba memproses pembayaran. Jika sukses, ia menerbitkan PaymentSucceeded; jika gagal, ia menerbitkan PaymentFailed. Ini adalah contoh klasik local transaction yang memicu local transaction berikutnya.
public interface IPaymentProcessor{ Task<string> AuthorizeAsync(Guid customerId, decimal amount);}public sealed class OrderCreatedHandler{ private readonly IPaymentProcessor _paymentProcessor; private readonly IMessageBus _bus; public OrderCreatedHandler(IPaymentProcessor paymentProcessor, IMessageBus bus) { _paymentProcessor = paymentProcessor; _bus = bus; } public async Task HandleAsync(OrderCreated message) { try { var paymentRef = await _paymentProcessor.AuthorizeAsync( message.CustomerId, message.TotalAmount); await _bus.PublishAsync(new PaymentSucceeded( message.OrderId, paymentRef)); } catch (Exception ex) { await _bus.PublishAsync(new PaymentFailed( message.OrderId, ex.Message)); } }}
Langkah 3: Inventory Service melanjutkan proses atau memicu kegagalan
Jika pembayaran sukses, Inventory Service akan menerima PaymentSucceeded, lalu mencoba reserve stok. Bila stok tersedia, ia menerbitkan InventoryReserved. Bila tidak tersedia, ia menerbitkan InventoryFailed. Ini adalah titik yang bagus untuk menunjukkan bagaimana choreography saga menangani branching flow secara event-driven.
public interface IInventoryService{ Task ReserveAsync(Guid orderId);}public sealed class PaymentSucceededHandler{ private readonly IInventoryService _inventoryService; private readonly IMessageBus _bus; public PaymentSucceededHandler(IInventoryService inventoryService, IMessageBus bus) { _inventoryService = inventoryService; _bus = bus; } public async Task HandleAsync(PaymentSucceeded message) { try { await _inventoryService.ReserveAsync(message.OrderId); await _bus.PublishAsync(new InventoryReserved(message.OrderId)); } catch (Exception ex) { await _bus.PublishAsync(new InventoryFailed( message.OrderId, ex.Message)); } }}``
Inilah salah satu kekuatan choreography: setiap service dapat memutuskan sendiri hasil langkahnya dan mempublikasikan fakta bisnis berikutnya. Namun di sisi lain, semakin banyak cabang dan kondisi kegagalan, semakin tersebar pula logika workflow ke banyak tempat. Hal ini sebagai salah satu kekurangan choreography untuk workflow yang makin kompleks.
Jika terjadi kegagal maka dapat membuat kompensasi melalui event
Sekarang mari lihat apa yang terjadi jika inventory gagal setelah payment sudah berhasil. Dalam saga, kita tidak melakukan rollback database global. Sebaliknya, kita menerbitkan event kegagalan (InventoryFailed) yang akan memicu compensating transaction di service yang relevan. Compensating transaction adalah langkah-langkah yang membatalkan efek dari langkah yang sudah dijalankan sebelumnya dalam operasi eventual consistency.
sequenceDiagram autonumber participant Order as Order Service participant Bus as Message Broker participant Payment as Payment Service participant Inventory as Inventory Service Order->>Bus: Publish OrderCreated Bus->>Payment: OrderCreated Payment->>Payment: Authorize payment Payment->>Bus: Publish PaymentSucceeded Bus->>Inventory: PaymentSucceeded Inventory->>Inventory: Reserve stock Inventory-->>Bus: Publish InventoryFailed Bus->>Payment: InventoryFailed Payment->>Payment: Refund / release authorization Payment->>Bus: Publish PaymentRefunded Bus->>Order: PaymentRefunded Order->>Order: Update status = Cancelled
Diagram ini menggambarkan esensi saga: ketika satu langkah gagal, kita memulihkan konsistensi bukan dengan rollback teknis lintas semua database, tetapi dengan aksi pembatalan yang dilakukan service-service terkait. Kompensasi tidak harus selalu berjalan dalam urutan terbalik persis, dan kompensasi sendiri perlu didesain agar andal serta idempotent.
Contoh handler kompensasi
Misalnya, Payment Service mendengar InventoryFailed lalu menjalankan refund atau release authorization. Setelah itu, ia menerbitkan PaymentRefunded, yang kemudian bisa dipakai Order Service untuk menandai order sebagai dibatalkan.
public interface IPaymentRefundService{ Task RefundAsync(Guid orderId);}public sealed class InventoryFailedHandler{ private readonly IPaymentRefundService _refundService; private readonly IMessageBus _bus; public InventoryFailedHandler(IPaymentRefundService refundService, IMessageBus bus) { _refundService = refundService; _bus = bus; } public async Task HandleAsync(InventoryFailed message) { await _refundService.RefundAsync(message.OrderId); await _bus.PublishAsync(new PaymentRefunded(message.OrderId)); }}public sealed class PaymentRefundedHandler{ private readonly IOrderRepository _orders; public PaymentRefundedHandler(IOrderRepository orders) { _orders = orders; } public async Task HandleAsync(PaymentRefunded message) { await _orders.UpdateStatusAsync(message.OrderId, "Cancelled"); }}
Pada sistem kompensasi seperti refund sering kali tidak sesederhana “set nilai kembali seperti semula.”. Kadangkala compensating transaction bisa sangat application-specific dan harus mempertimbangkan aturan bisnis, misalnya refund parsial, status settlement, atau notifikasi manual jika kompensasi tidak dapat diselesaikan otomatis.
Tantangan implementasi (Idempotency)
Dalam distributed system, duplicate delivery dan retry adalah hal yang normal. Perlu diperhatikan bahwa saga harus mampu menangani transient failure dan menjamin idempotence, yaitu pengulangan operasi yang sama tidak mengubah hasil akhir. Tanpa idempotency, event yang terkirim dua kali bisa menyebabkan efek samping ganda seperti stok berkurang dua kali atau refund dikirim dua kali.
Contoh sederhana implementasi idempotent pada .NET:
public interface IInboxStore{ Task<bool> ExistsAsync(Guid orderId, string messageType); Task MarkProcessedAsync(Guid orderId, string messageType);}public sealed class IdempotentOrderCreatedHandler{ private readonly IInboxStore _inbox; private readonly IPaymentProcessor _paymentProcessor; private readonly IMessageBus _bus; public IdempotentOrderCreatedHandler( IInboxStore inbox, IPaymentProcessor paymentProcessor, IMessageBus bus) { _inbox = inbox; _paymentProcessor = paymentProcessor; _bus = bus; } public async Task HandleAsync(OrderCreated message) { if (await _inbox.ExistsAsync(message.OrderId, nameof(OrderCreated))) return; var paymentRef = await _paymentProcessor.AuthorizeAsync( message.CustomerId, message.TotalAmount); await _inbox.MarkProcessedAsync(message.OrderId, nameof(OrderCreated)); await _bus.PublishAsync(new PaymentSucceeded(message.OrderId, paymentRef)); }}
Tantangan implementasi (Exception handling dan retry)
Karena saga berbasis messaging, developer tidak boleh gegabah menangkap exception lalu menganggap semuanya selesai. Bila exception tidak dipropagasikan atau tidak di-handle dengan benar oleh infrastruktur retry, pesan bisa dianggap berhasil diproses padahal sebenarnya gagal. Rekomendasi strategi untuk menangani transient failure secara efektif dan meminimalkan kebutuhan kompensasi dengan retry yang tepat.
Tips praktisnya:
- Gunakan retry untuk kegagalan sementara.
- Gunakan dead-letter atau manual intervention untuk kegagalan permanen.
- Pastikan kompensasi sendiri juga aman diulang jika sempat gagal di tengah jalan.
Tantangan implementasi (Message ordering dan data anomaly)
Saga tidak menyediakan isolasi ACID otomatis. Karena tiap service mengelola data sendiri, anomali seperti lost update, dirty read, atau nonrepeatable read dapat terjadi jika beberapa saga berjalan bersamaan atau jika data berubah di tengah alur. Tantangan message ordering dalam sistem terdistribusi. Artinya, desain saga yang baik perlu mempertimbangkan semantic lock, optimistic locking, reread values, atau teknik lain sesuai risiko bisnis.
Ini juga yg menjadi alasan mengapa choreography cocok untuk flow yang relatif sederhana. Begitu domain punya banyak dependensi, banyak cabang, dan risiko konflik tinggi, pendekatan orchestration sering menjadi lebih mudah dikelola, dan itulah yang akan kita bahas pada selanjutnya.
Choreography-based saga adalah cara yang elegan untuk membangun transaksi terdistribusi di microservices tanpa distributed transaction tradisional dan tanpa orchestrator pusat. Setiap service cukup fokus pada local transaction ditambah dengan event yang dipublikasikan, lalu service lain melanjutkan flow berdasarkan event itu. Pendekatan ini sangat cocok untuk arsitektur .NET yang sudah event-driven dan selaras dengan lingkungan cloud seperti Azure. Namun keuntungan loose coupling ini juga harus dibayar dengan meningkatnya kebutuhan terhadap idempotency, observability, error handling, dan pemahaman flow lintas banyak service.
Pada Part 3, kita akan membahas alternatif lainya yaitu Orchestration-Based Saga. Jika choreography adalah tarian tanpa sutradara tunggal, maka orchestration adalah alur yang dikendalikan oleh seorang conductor.

Leave a comment